
The Agent Stack is Forming
Open models, crypto wallets, and the infrastructure for autonomous AI

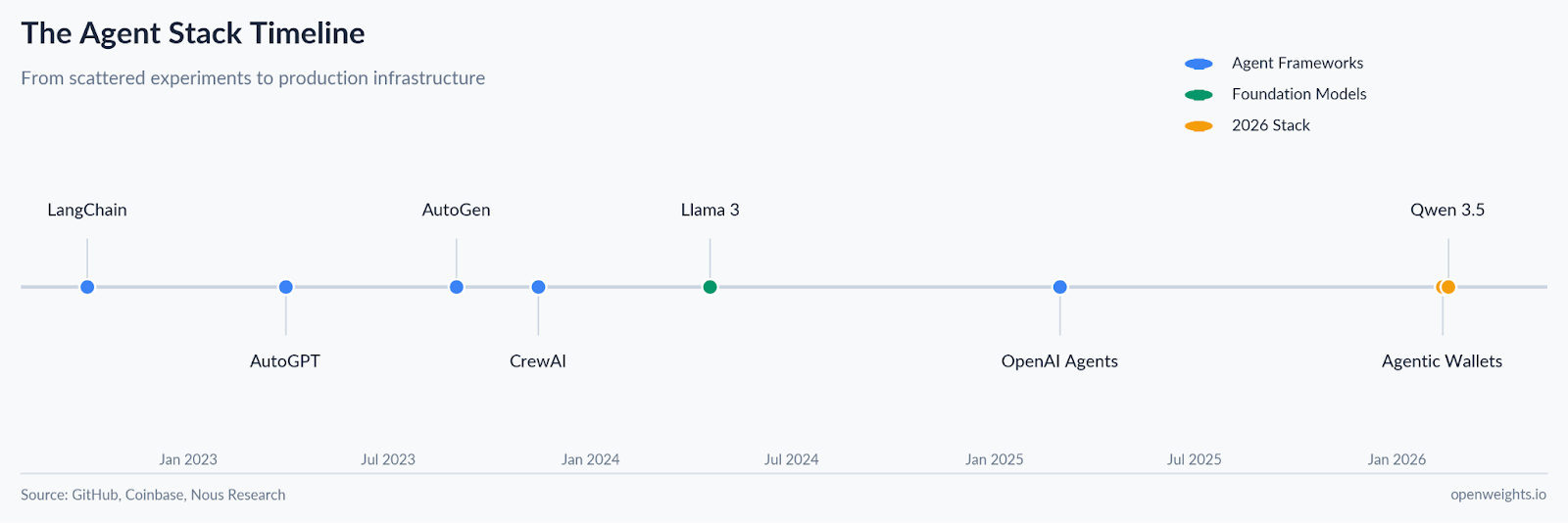
The Agent Stack is Forming
Nous Research dropped Hermes Agent, an autonomous agent that lives on your server and learns from its mistakes. Hermes Agent isn’t better than Claude or Codex, but it does have some interesting things running under the hood.
Hermes provides a framework for building agents that compound their capabilities over time. Atropos tracks what the agent does and what works. Tinker trains LoRAs based on those results. The agent runs experiments on itself, sees what fails, trains a fix and deploys it.

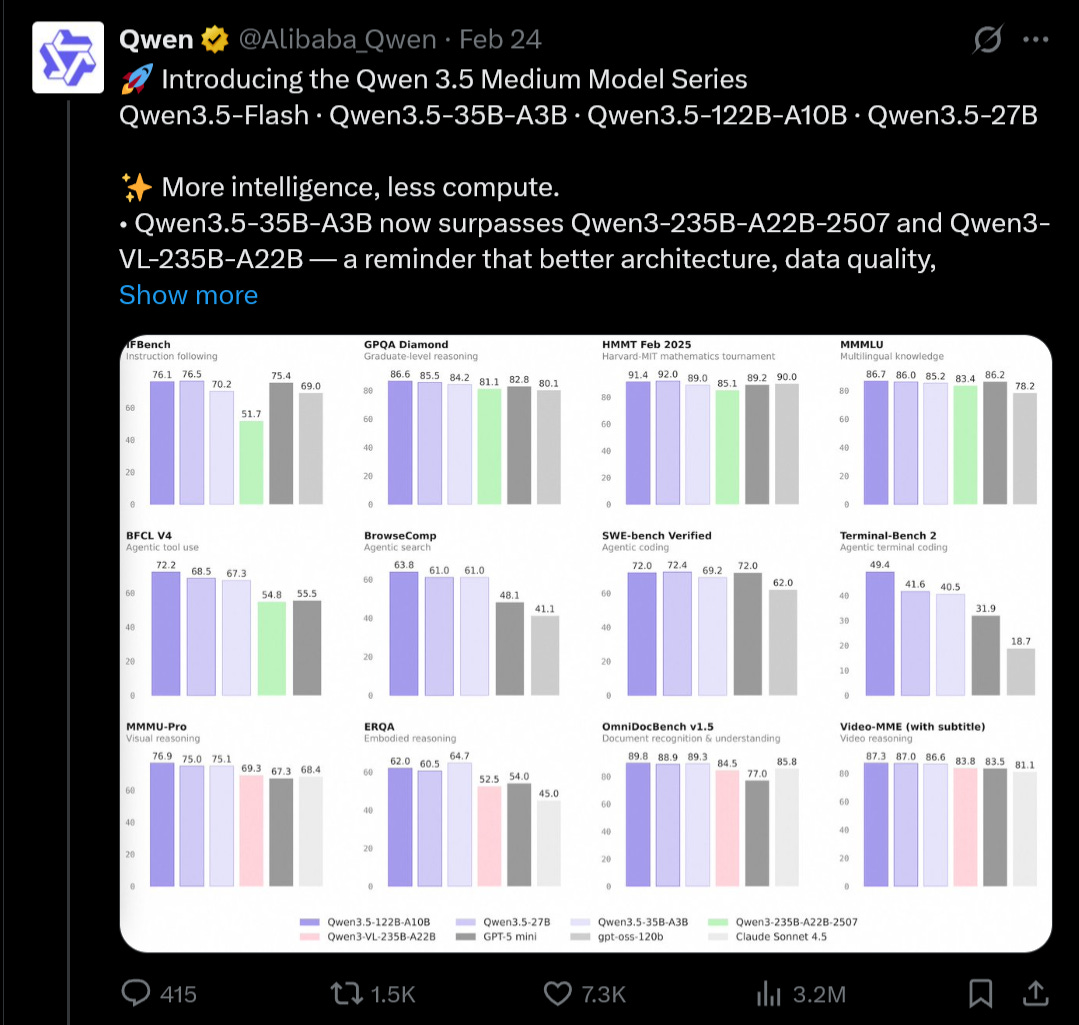
Qwen 3.5 makes local inference more practical. The 35B-A3B model activates only 3 billion parameters at inference which means it could run on a single RTX 3090. Local LLMs have notoriously been difficult to run so this is genuinely exciting news. Local models have been technically possible but difficult in practice. Qwen 3.5 is another step forward for closing that gap.
GGML and llama.cpp joined HuggingFace this week. The most-used local inference tools now live alongside the model hub. The infrastructure for running models locally is consolidating.
Coinbase also announced Agentic Wallets which lets your agent hold funds, send payments, trade tokens, and earn yield without a human in the loop. Built on x402, the wallet already includes programmable guardrails like session caps, transaction limits, and rules for when an agent can spend and how much.
Until now you could build an agent that remembered context but couldn’t transact. That wall is down now. OpenAI and Stripe have ACP, Google announced UCP in January, Mastercard is rolling out Agent Pay. Coinbase’s approach stands out as the most builder-friendly with permissionless infrastructure on crypto rails.
Discovery
PicoLM is a framework for running 1-billion parameter models on boards with 256MB of RAM. The project targets $10 microcontrollers and edge devices that couldn’t run LLMs before. It combines aggressive quantization with a custom C inference engine, bypassing Python and CUDA entirely.
PicoLM runs entirely on the device, which makes it useful for places without reliable internet or for users who don’t want their prompts logged on someone else’s server. The repo has already crossed 1,000 stars on GitHub.
Google Research’s TimesFM is a foundation model for time series forecasting. Feed it historical data, get predictions. Sales, server load, inventory, energy demand, stock prices.
Builder Tip: Queue Work, Don’t Chat
Most people interact with AI through conversation but this doesn’t scale. You are stuck doing one task at a time.
Recently, I built out a task queue so I can do multiple tasks at a time. I have Claude write a brief spec about what I want and Claude drops it off in the task queue where it gets assigned to a worker. The agent picks it up, works through it, and lists every file it modified when it’s done. You review the output against the spec instead of watching it work.
It sounds like a small change at first but it opens up asynchronous work which is a big shift. You don’t have to wait for an agent to finish before continuing the prompt. You get your time back and the agent gets clear instructions instead of a conversation to interpret.
Global AI Watch
Chinese open-source models now account for roughly 13% of inference on OpenRouter, peaking at nearly 30% during high-traffic periods. Qwen has reportedly overtaken Meta’s Llama in Hugging Face downloads, and DeepSeek usage spiked after their reasoning models dropped. Pricing varies by provider, but Chinese models often undercut US alternatives significantly.
Best Thing I Read
Working with documents in LLMs usually means stuffing them into context every query or fine-tuning, and both are slow. Doc-to-LoRA takes a different approach: a hypernetwork converts documents into LoRA adapters in under one second, which then merge into the model so it “knows” the content without needing it in context.

They tested on documents up to 40K tokens despite only training on 256-token sequences, hitting about 85% of full-context accuracy. It’s early research and not production-ready, but for anyone building agents that need persistent memory over documents, this is the direction worth paying attention to.